Dec 17, 2025
AI News and Outlook for 2026

Here’s what caught my attention in AI research lately, and where things might be heading in 2026.
After 25+ years in this field, the pace has gotten hard to keep up with. I’m trying to make sense of what actually matters from the flood of papers and demos. One thing that’s become obvious: AI can now handle far more complex questions than before. What used to be simple search has turned into systems that actually understand what you’re asking and figure out whether they need to look something up, reason through it, solve a problem, or spin up a whole agent workflow.
The shift is dramatic. We’ve gone from systems that could barely handle simple Q&A to agents that can solve complex multi-step problems, navigate open-ended environments, and even play sophisticated games while continuously learning and adapting. This progress spans multiple fronts: better reasoning architectures, improved memory systems at all levels (from working memory to long-term episodic storage), and world models that now incorporate actions — not just passive observation, but active interaction with environments and prediction of consequences.
This convergence is particularly driving robotics forward. When you combine better reasoning, persistent memory, and world models that understand cause and effect through actions, you get systems that can actually operate in the real world rather than just simulate it.
Note: I’m planning a separate blog post on what’s new in recommender systems — there were too many great contributions at RecSys 2025 alone, and I need more time to properly explore all the papers.
Measuring Intelligence
Large language models are everywhere now, which raises an obvious question: how do we actually measure intelligence? Most benchmarks test specific skills, but real intelligence means generalizing, reasoning, and adapting to situations you haven’t seen before.
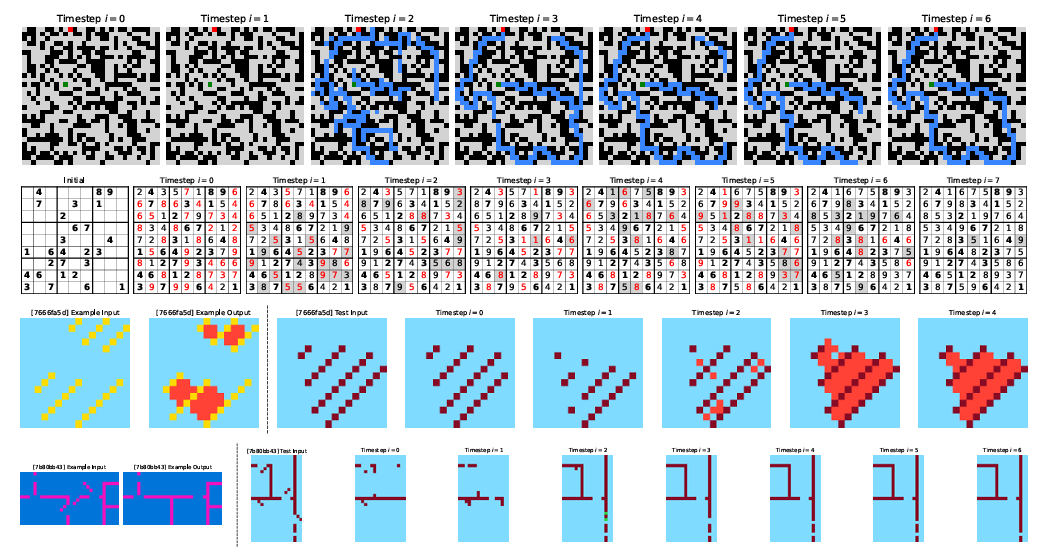
The Abstraction and Reasoning Corpus (ARC-AGI) (arcprize.org) tests whether AI can actually generalize beyond what it was trained on. It started as visual pattern puzzles but also applies to language tasks. The idea is fluid intelligence — can you learn a simple rule from a few examples and apply it to new cases? (Chollet, 2019)

ARC-AGI tasks are easy for humans (often solvable in one or two tries) but extremely challenging for LLMs. Over 2025, model performance finally exceeded 90% on ARC-AGI-1. Other, less well-known benchmarks are still unresolved — for example CritPT, where even frontier LLMs perform poorly despite excelling on standard benchmarks.
ARC-AGI-2 and Beyond
ARC-AGI-2 (Chollet et al., 2025) raises the bar. It resists brute-force search and requires compositional generalization — combining rules in new ways across larger grids. Humans solve these tasks in about 2.7 minutes on average, but AI systems still struggle with rule composition.
ARC-AGI-3 is the next step: interactive environments where agents have to perceive, decide, and act without being told what to do. Can AI infer the goal by exploring?

The pattern is clear: AI is great at pattern matching but still weak at robust reasoning and open-ended learning of the kind humans do naturally.
Refinement Loops
The winning teams of the 2025 ARC Prize relied on outer-loop refinement, test-time fine-tuning, and synthetic data techniques rather than pure scaling.
A refinement loop is simple: propose a solution, evaluate it, refine based on feedback, repeat until it works. This approach proved to be very beneficial. Teams like MindsAI (3rd place) used test-time training, while ARChitects(2nd place) applied recursive self-refinement with 2D diffusion.
The NVARC solution involved extensive data engineering, enabling the training of a highly efficient 4B reasoning model, combined with novel recursive architectures (see below).
Larger closed-source models such as GPT-5.2 still outperform these smaller, more elegant systems by a large margin, but the resource asymmetry is significant.
Recursive Transformers
A recurrent transformer reuses some or all of its blocks across multiple iterations. Instead of stacking many different blocks, a smaller set is applied repeatedly with shared weights. (TRM paper)
Hierarchical Reasoning Model (HRM)
HRM (paper, GitHub) is a nested recurrent transformer with two time scales: a fast loop for refinement and a slow loop that updates global state.
HRM does this with just 27M parameters and 1,000 training samples, yet outperforms much larger models on reasoning benchmarks. The TRM paper shows similar results — a 7M recursive model can outperform models with 100× more parameters by encoding multi-step reasoning through iteration instead of learning it implicitly.
Open-Ended Learning: The SIMA 2 Agent
Open-ended learning refers to systems that keep acquiring new skills and goals without being limited to a fixed set. Unlike standard multi-task reinforcement learning with predetermined tasks, an open-ended learner generates its own objectives and learning signals.
SIMA 2: Scalable, Instructable, Multiworld Agent
SIMA 2 from DeepMind is an embodied agent that plays 3D games like a human. It was trained on 20+ environments with hundreds of skills and generalizes to new games like ASKA and MineDojo without extra training. It improves by proposing its own tasks and evaluating success autonomously.
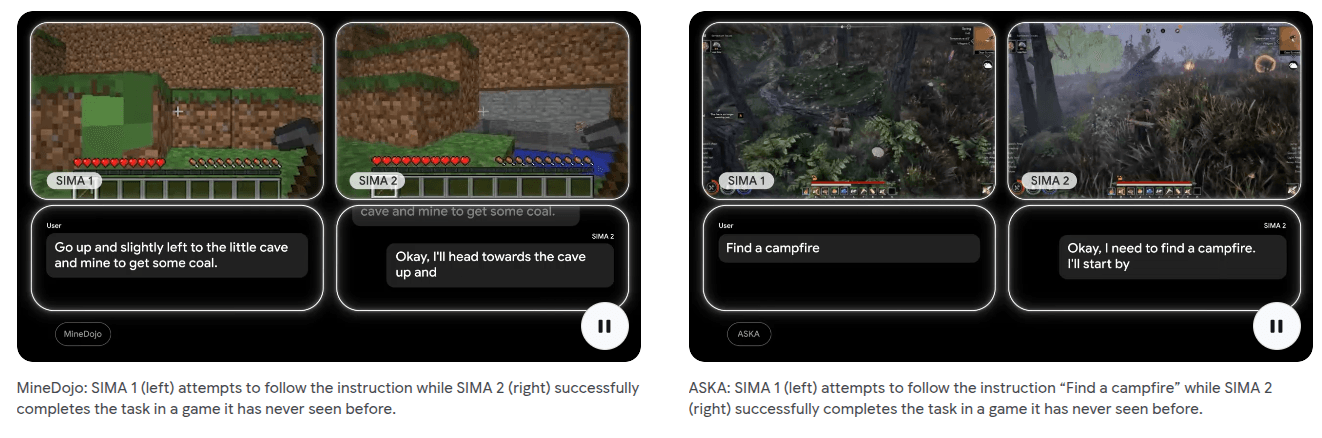
SIMA 2 operates in a loop: perceive (visual + text), reason and plan, act, observe feedback, update policy, repeat. It uses internal reasoning blocks for chain-of-thought planning, has around 4k token context windows with short-term episodic memory, and replay buffers, and lets the LLM both propose tasks and evaluate success.
The results are great: a raw Gemini model achieves 3-7% success, while SIMA 2 reaches near-human performance. Vision-action integration and structured learning matter far more than model size alone.
Scaling Agent Systems
As AI systems improve, a practical question emerges: when does it make sense to use multiple agents instead of a single one?
Multi-agent systems work best on parallelizable tasks. Finance-Agent’s centralized multi-agent system achieved an 81% improvement over a single agent by using specialized roles such as researcher, analyst, and executor. However, on tightly coupled sequential tasks, multi-agent setups can perform worse due to coordination overhead.
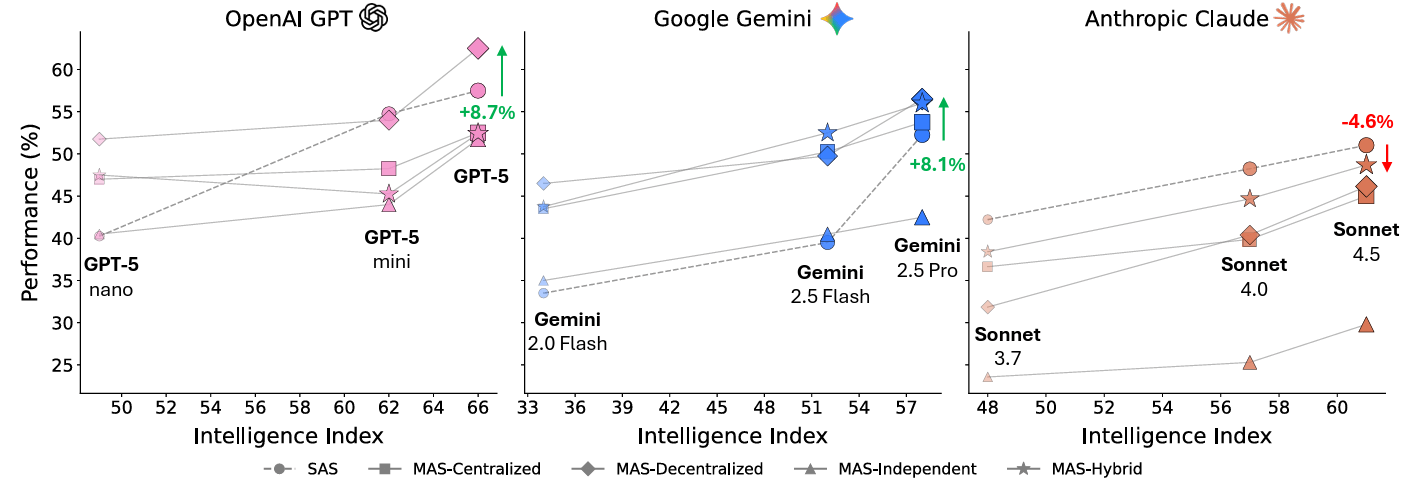
The lesson is that task decomposability matters a lot. Multi-agent approaches work when tasks can be cleanly split and parallelized Coordination costs grow super-linearly, and capability saturation is real: if a single agent is already strong, adding more agents can yield diminishing or even negative returns (Scaling Multi-Agent Systems). Specialization consistently beats redundancy and diversity in agentic systems is as important as in model ensembles.
Memory Architectures: Beyond Context Windows
As AI tackles increasingly complex, long-term tasks, the limitations of current memory systems become clear. Unlike humans, who can recall specific conversations, learn incrementally without forgetting, and build rich episodic memories, LLMs suffer from catastrophic forgetting, hallucinate facts, and lack persistent personal memory across sessions.
For AI to truly collaborate with humans over long periods, it needs human-like memory: the ability to form lasting relationships, remember individual preferences and context, learn continuously without losing old knowledge, and distinguish between what it knows with certainty and what it is uncertain about. This drives the need for new memory architectures that separate reliable facts from uncertain inferences, maintain persistent identity across interactions, and support lifelong learning.
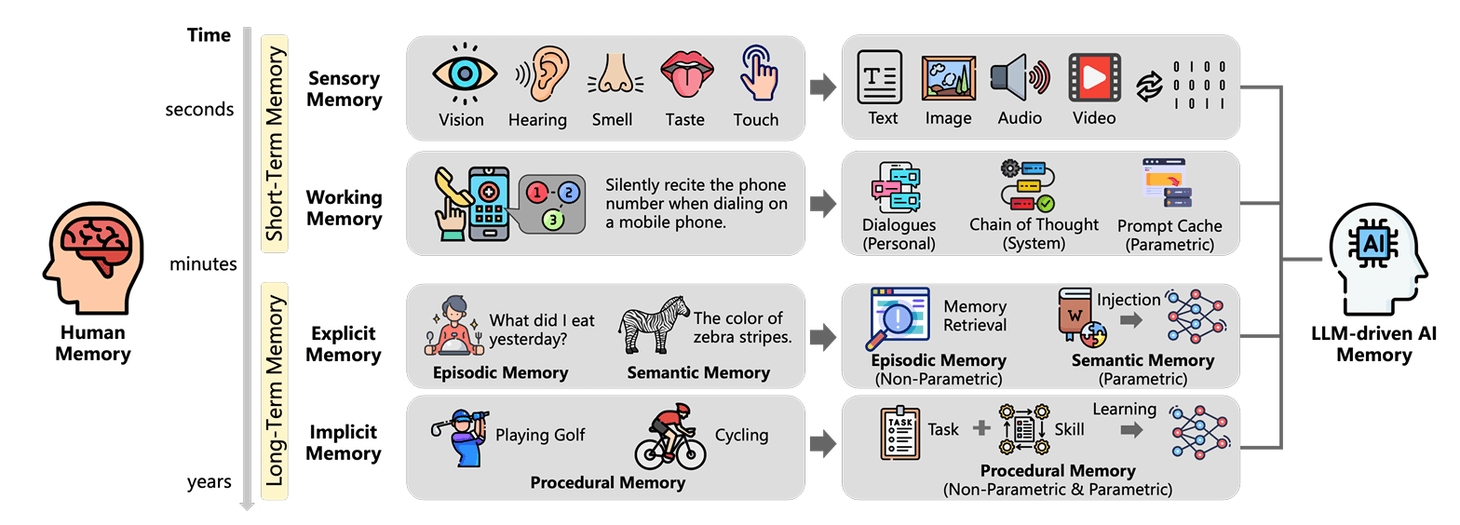
Modern AI memory can be classified along three dimensions: object (personal vs. system), form (parametric vs. non-parametric), and time (short-term vs. long-term). This results in eight memory quadrants, each with distinct roles, analogous to human memory types. (Memory Taxonomy Survey)
Nested Learning: Continuous Memory
Nested Learning from Google Research (NeurIPS 2025) represents an interesting direction in memory architecture design. Traditional AI systems separate model parameters from learning algorithms, whereas nested learning creates a unified memory hierarchy in which different layers learn at different timescales and retain information at multiple levels of abstraction.
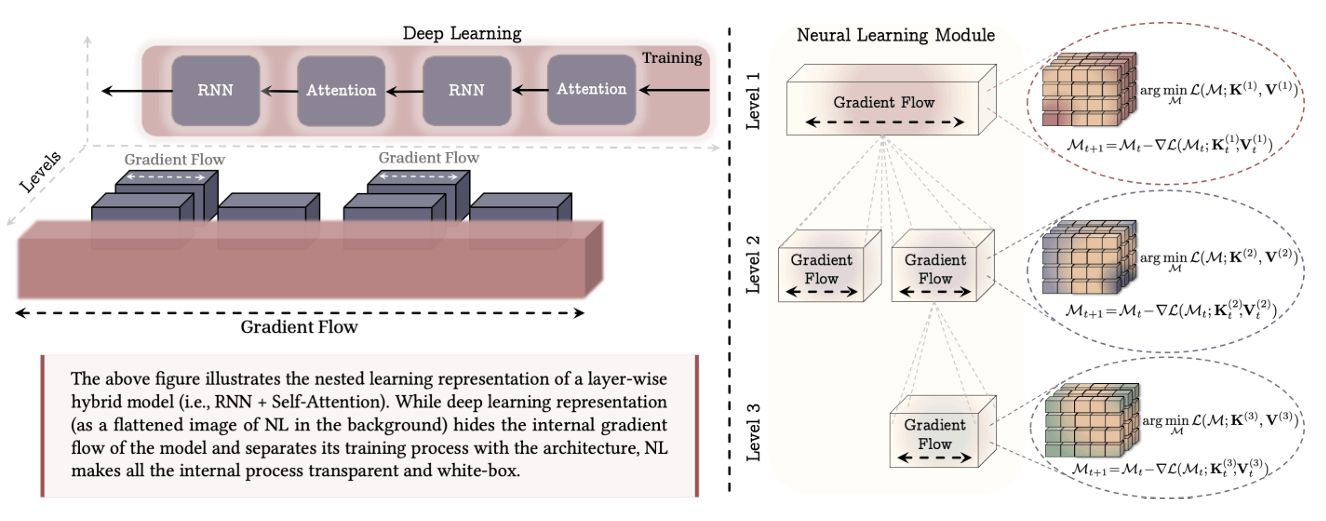
This memory architecture enables continuous adaptation without catastrophic forgetting: inner loops handle fast adaptation to immediate tasks, while outer loops preserve long-term knowledge. The result is a system that naturally balances stability and plasticity, making it well suited for lifelong learning scenarios in which AI agents must retain past experiences while adapting to new environments.
MemoryOS and A-MEM
MemoryOS is a memory operating system for AI agents, inspired by operating system memory management. It has three levels: Short-Term Memory (hot, similar to a cache for recent dialogue), Mid-Term Memory (warm, storing summaries and important segments), and Long-Term Memory (cold, large-scale persistent storage).
A-MEM (Adaptive Memory for Embodied Multimodal Agents) introduces a memory architecture with three integral components in memory storage. During note construction, the system processes new interaction memories and stores them as notes with multiple attributes. The link generation process retrieves the most relevant historical memories and uses an LLM to determine whether connections should be established between them. The concept of a 'box' describes how related memories become interconnected through similar contextual descriptions. Individual memories can exist simultaneously in multiple boxes. During retrieval, the system extracts query embeddings using a text encoding model and searches the memory database for relevant matches. When a memory is retrieved, related memories linked within the same box are automatically accessed.
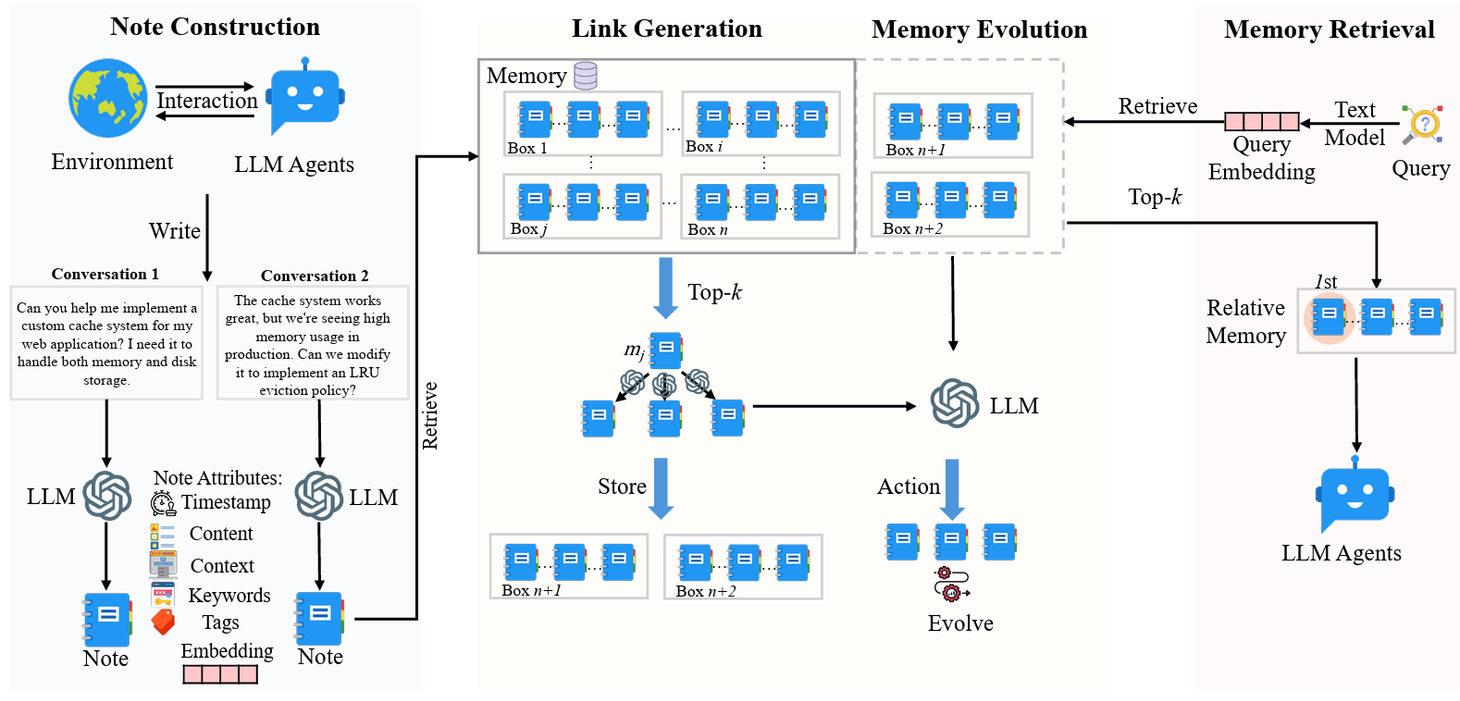
These memory systems are becoming essential as AI tackles increasingly complex, long-term tasks that require reliable retention and retrieval.
World Models: From Video Generation to Robotics
As AI systems increasingly need to plan and generalize to solve new tasks, world models are becoming more important. These systems predict future environment states and are evolving from simple predictors into systems that generate realistic video, capture physical dynamics, and control robots.
Video Generation as World Modeling
Models like Sora from OpenAI, Veo from Google DeepMind, and HunyuanVideo from Tencent show that video generation models can act as world simulators (see World Models paper). They learn physics, object permanence, and causal relationships from large-scale video data, which changes how we think about AI interaction with the physical world.

Vision-Language-Action (VLA) Models for Robotics
A VLA model is a foundation model that takes visual input, processes language commands, and outputs actions to control an agent. Vision + language + action equals powerful embodied AI.
DeepMind’s Gemini Robotics (2025) and NVIDIA GR00T N1 demonstrate what VLA models can achieve in real-world settings.
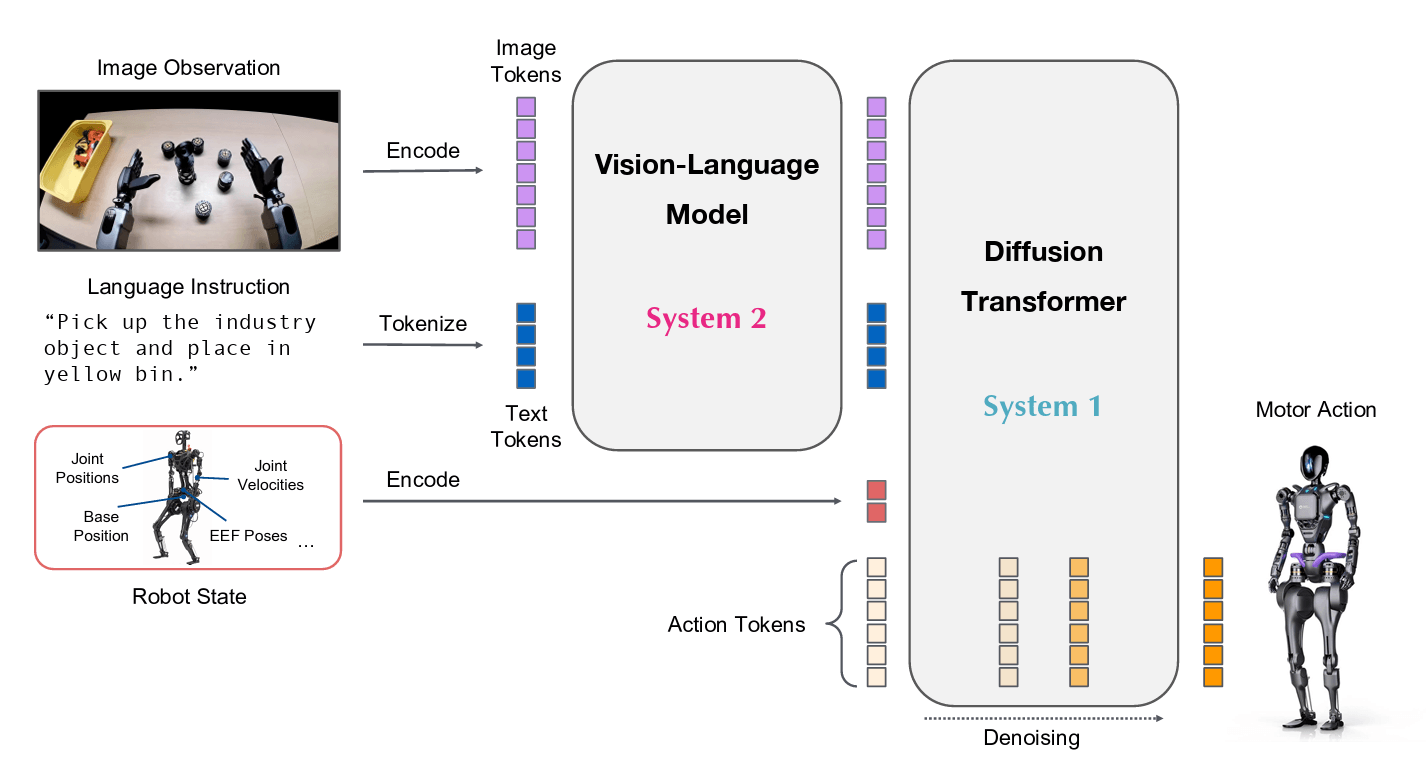
These systems can perform tasks that seemed impossible just a few years ago. They handle open-vocabulary instructions (not just fixed commands), remain robust to novel objects and unstructured environments, adapt to new tasks from roughly 100 demos, and transfer capabilities from two-armed systems to humanoid robots.
Robotics is the ultimate test because it requires AI to handle real-world complexity — not just generating pixels, but manipulating physical objects under real constraints such as geometry, friction, and randomness. The model’s internal representations must align with physical reality.
What Lies Ahead in 2026?
Predicting AI is getting harder, but here’s what I’m seeing based on current trends.
Looking ahead to 2026, several key trends are likely to shape AI progress:
- Reasoning benchmarks will diversify beyond current limitations. ARC-AGI-3 will introduce interactive elements, while new benchmarks emerge in physics simulations, advanced mathematics, and agentic collaboration involving multiple AI systems working together.
- Open-ended learning will expand into multi-agent environments where general agents compete with specialized models, increasing the importance of collaboration, competition, and communication as we move toward AI societies.
- Memory architectures will advance through hierarchical memory stacks (hot-warm-cold), nested learning, and continuous learning without catastrophic forgetting, alongside more realistic benchmarks with practical constraints.
- Robotics will see growing competition between general-purpose humanoid agents and specialized hardware, leading to a foundational model zoo for on-device AI that includes smaller efficient models, specialized hardware, and hybrid systems.
- Cloud AI ecosystems will explode with reasoning-as-a-service, memory-as-a-service, and world-model-as-a-service components that can be composed like building blocks.
- Process innovation will continue to outpace raw scale, with more test-time training, refinement loops, evolutionary problem-solving, and smarter inference-time compute.
- Finally, a benchmark revolution will bring more realistic evaluation beyond static puzzles, including interactive and dynamic assessments, collaboration benchmarks, and cross-domain testing across physics, math, and logic.
Beyond 2026
With all these advances, we are heading toward an era of proactive digital assistants. They won’t be passive anymore — they’ll advocate, plan, and act on our behalf. People who invest in better assistants are likely to become more efficient and more competitive, as their systems operate for them in the digital world.
These assistants will be connected to the internet, improving themselves with real-time information and iteratively refining their outputs and actions. Access to validated information and high-quality data will increasingly become a decisive advantage.
The convergence of abstract reasoning (ARC), world modeling (SIMA), memory mechanisms, and physical embodiment points toward AGI systems that can understand instructions, maintain world models, plan long-term, learn continuously, and act in the real world.
We also need to identify the right interfaces between humans and AI. Not everyone wants neural implants, and people are still hesitant to communicate with machines purely through natural language — perhaps because machines have only recently begun to understand us. Either way, this transition will take time. Careful experimentation will be needed to ensure these technologies genuinely improve efficiency and quality of life.
Here’s to 2026 — potentially the beginning of a full-scale technological AI revolution. If handled well, it is likely to bring more good than harm, and we all have a role to play in shaping it.
Further Reading
- ARC Prize — The competition and benchmarks
- ARC-AGI-2 Paper — Chollet et al., 2025
- HRM Paper — Hierarchical Reasoning Model
- SIMA 2 — DeepMind’s Scalable Instructable Multiworld Agent
- Scaling Agent Systems — When multi-agent helps vs. hurts
- Memory Taxonomy Survey — 3D-8Q taxonomy
- Nested Learning — Google Research, NeurIPS 2025
- Gemini Robotics — Vision-Language-Action for robots
- GR00T N1 — NVIDIA’s humanoid robot model
- CritPT Benchmark — Critical thinking evaluation
- GPT-5.2 — OpenAI’s latest model
- TRM Paper — Recursive reasoning with tiny networks
Next Articles

Product Highlights from 2025
In 2025, we focused on making advanced personalization easier to implement, scale, and maintain across products and platforms. Here’s a look at the key product updates we released last year.
Jan 08, 2026

Recombee Partners with The Telegraph to Deliver AI-Driven Personalisation to Millions of Readers
Prague, 11th September 2025 – Recombee, a leading AI-powered recommendation platform, has announced a strategic partnership with The Telegraph...
Oct 02, 2025

Modern Recommender Systems - Part 3: Objectives
Learning objectives of recommender systems and personalized search.
Sep 03, 2025