Mar 01, 2024
Is This Comment Useful? Enhancing Personalized Recommendations by Considering User Rating Uncertainty
Picture this: you're on the hunt for the perfect new smartphone, browsing through your favourite online electronics store. The online store’s recommendation engine pops up with what it thinks could be your possible next gadget love. You narrow down your options and, to ensure you're making the right choice, you dive into the reviews. Then you find the two reviews below, both awarded five out of five stars for the same smartphone:
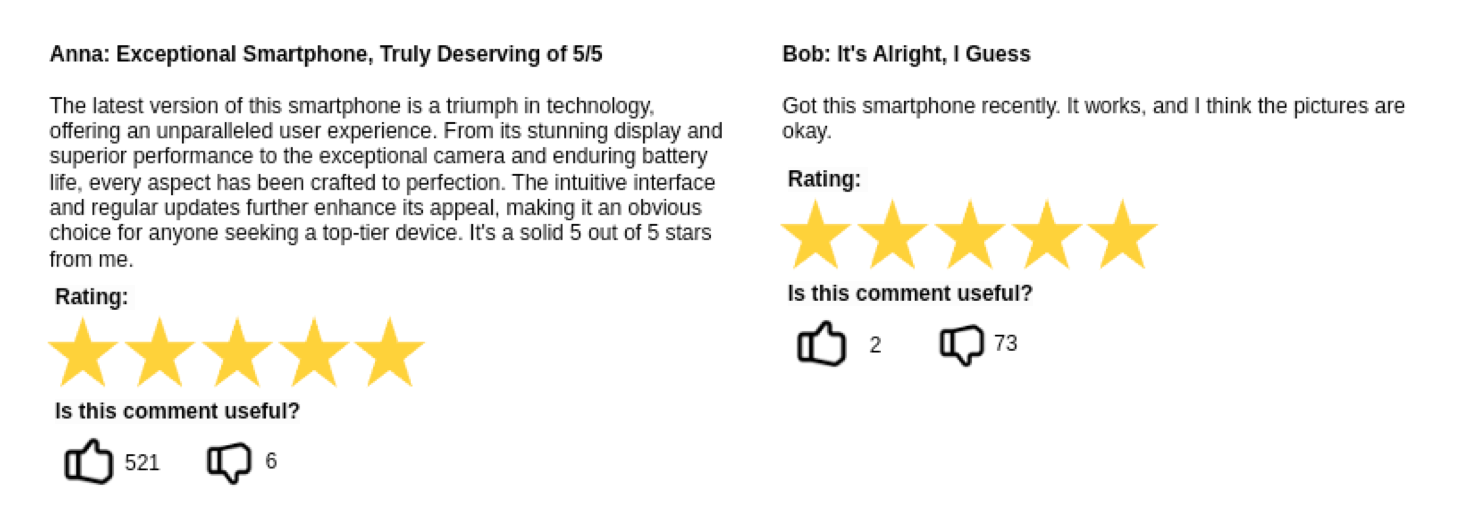
You probably have faced this situation before. On one hand, the review of Anna is detailed, citing specific features, performance metrics, and personal experiences with the phone. It reads like the user has really put the phone through its paces and knows what they're talking about. The Bob’s review, on the other hand, is vague and non-committal, offering little beyond a general sense of satisfaction. Instinctively, you're more inclined to trust the first reviewer's opinion. Their thoroughness and confidence suggest they're well-informed, making their review a valuable piece of your decision-making puzzle. But here's the million-dollar question: will the recommendation system take this disparity in review depth and confidence into account when suggesting your next potential purchase?
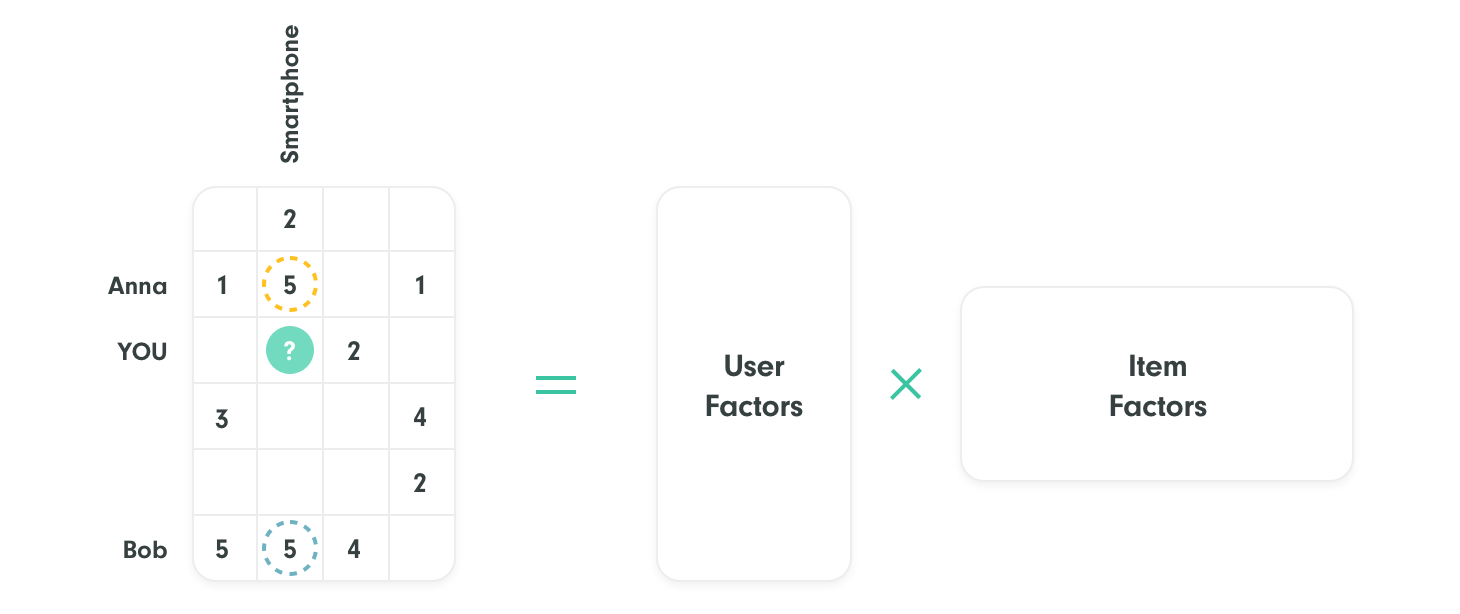
Unfortunately, the answer is: not frequently! Traditional methods almost never take such properties into account when evaluating users' feedback. Let’s take the example of recommender systems (RSs) based on matrix factorization (MF) methods, a very popular and efficient and accurate way of providing personalised user experiences by aggregating collective feedback. In the explicit feedback setting, where users explicitly rate part of the items set (as described in the figure above), the RSs rely on the ratings matrix, where rows (resp. columns) represent users (resp. items) and only a small proportion of the entries (user-to-item ratings) are observed. To provide customised recommendations, an MF recommender performs the following two steps: (1) factorise the ratings matrix in order to predict the large set of unrated ratings using an MF method, and (2) rank the items for each individual user based on the predictions. When new feedback arrives, the system restarts the described cycle from the beginning, resulting in a newly trained model with the potential to improve the recommendation accuracy.
Although MF recommenders are often efficient and accurate, they are highly dependent on the quality of the users' feedback. On the one hand, clear and consistent feedback supports the algorithm's ability to filter collaborative behavior. Noisy or anomalous feedback, on the other hand, can induce the learning method to misinterpret users' preferences, potentially leading to suboptimal recommendations. Since users frequently perceive rating as a tedious process, certain inconsistencies in the data are unavoidable. In MF methods this type of vulnerability to noise is especially complex: the predictions for all of the users are related to each other, and strong noise in one user (or item) can influence and propagate through the predictions of the entire model. However, classic MF methods do not adapt to the noise in user-item ratings or factor the uncertainty into the model. Even the simple fact that some users are (or less) confident in their judgement is typically neglected. By giving the same importance to the ratings of all users (both normal and anomalous), the learning method can be notably affected if a substantial number of users provide evidently erratic feedback. Crucially, unlike other machine learning methods, inaccurate ratings and noise in recommender systems can be highly structured in their dependence on the input. In simpler terms, these systems only look at the numerical rating a user leaves, ignoring any written comments. Even though these comments could offer valuable insights for making better recommendations in the future, they're not taken into account. The factorization of our smartphone example is illustrated in the figure below:
How to deal with this problem? Previous attempts at dealing with so called natural noise management in RSs can be classified into two types: those that rely solely on rating values and those that require extra side information for noise detection. The primary objective of the first group is to detect noisy ratings by analysing their distribution regarding a particular user and/or item. They then use a collaborative filtering strategy to predict unobserved ratings by only considering denoised and noise-free items. The second group, on the other hand, utilises item attributes to detect users' inconsistent behaviour when rating similar items and, then, correct the rating predictions. Despite their important contributions, neither trend concentrated on weighting the loss function to directly inject knowledge about the uncertainty attached to the quality of user ratings into the model. Indeed, existing methods simply ignore user, items or ratings which they deem anomalous, instead of providing a model-based directly on a continuous notion of reliability or noisiness. More importantly, the few results in this branch of research which pertain to MF approaches are entirely empirical and no theoretical guarantees were given.
Recently, we present a matrix factorization method that uses side information in the form of an estimate of the user's uncertainty to deliver more robust predictions. Our paper was published in the renowned IEEE Transactions on Neural Networks and Learning Systems journal [1]. The two main technical improvements are the introduction of a weighting on the loss function and a modified regularisation strategy aimed at controlling any negative effects of this injected form of non-uniformity.
How we do that? We postulate that more comprehensive reviews made by a particular user indicate that he/she/they is meticulous in his/her/their evaluations and thus may consistently generate less noise during the rating process. We reinforce the feedback from such users who appear to demonstrate a higher standard of thoroughness and trustworthiness in the assessment of the items they interact with. To achieve this aim, we construct weights for each user indicating the degree of trustworthiness of their reviews, and use them to re-weight the empirical estimate of the loss function. The weight will be higher if we estimate that their predictions are an accurate reflection of a consistent taste and lower if their rating behaviour appears erratic. However, this does not mean that users deemed the most "trustworthy" must produce ratings which agree with each other, but rather that they are not subject to outside noise not directly related to the user-item combination. In other words, we give more importance to users which consistently gives consistent comments together with their feedback. In a mathematical sense, our loss function differentiate from traditional matrix factorization as the following:

For a deeper dive into the technicalities, specially regarding our modified regularisation procedure, we invite you to read our paper.
Yet, a pivotal question remains: how do we determine the weight of each user's input in the loss function? The methodology can significantly differ based on the specific use case. Options include organizing comments with sophisticated large language models or assigning greater importance to more elaborate and comprehensive feedback. Alternatively, we could directly seek user opinions to assess the relevance of their contributions. Note that in our model, the weights are related to each user; this means that we do not need to observe reviews for all items the user interacts with, but typically just a few are enough. Investing in research is crucial here, as it enables us not only to utilize existing technologies but also to innovate and tailor solutions to meet individual client needs.
References
[1] Alves, R., Ledent, A., & Kloft, M. (2023). Uncertainty-adjusted recommendation via matrix factorization with weighted losses. IEEE Transactions on Neural Networks and Learning Systems.
Next Articles

Recombee Real-Time AI Recommendations as the New Destination in Segment
Segment has enabled its users to enjoy Recombee personalization services without the need to leave their platform and with minimum coding involved. With a few simple clicks, domains using Segment can upgrade their services to maximize the digital experience for their customers.
Mar 05, 2024

Recombeelab's 2023 Research Publications
Recombeelab, a joint research laboratory of Recombee and the Faculty of Information Technology at the Czech Technical University in Prague, experienced a highly productive year in 2023, publishing a series of insightful and impactful papers in the field of recommendation systems.
Jan 19, 2024

AI News and Outlook for 2024
We look at the most interesting research directions and assess the state of knowledge in key areas of AI. We'll also estimate future developments in 2024 so you know what to prepare for.
Jan 16, 2024